Algorithmic Strategies for Linked Lists
Master the most common algorithmic strategies to solve linked list problems in LeetCode. Learn how to identify patterns and apply the right approach with real C# implementations.
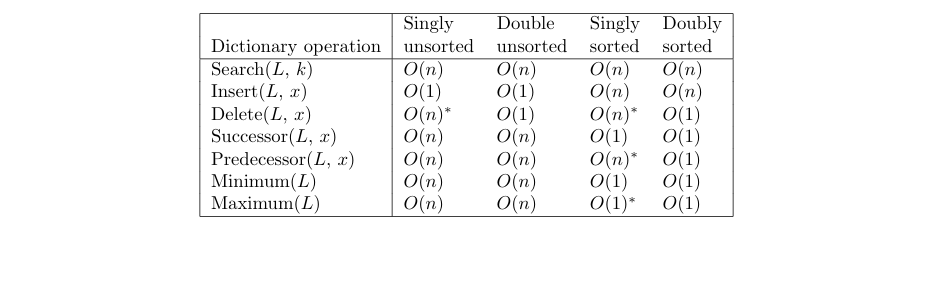
Introduction
Linked Lists are a fundamental linear data structure where elements are stored in nodes, and each node points to the next node in the sequence. The key to solving linked list problems efficiently is recognizing patterns and applying the right algorithmic strategy. This guide explores the most common strategies with real C# implementations from LeetCode problems.
Common Algorithmic Strategies
When approaching linked list problems, you’ll typically encounter one of these strategies:
- Two Pointers (Fast & Slow): Efficiently traverse with pointers at different speeds
- Floyd’s Cycle Detection: Detect cycles using tortoise and hare algorithm
- Recursion: Leverage the recursive nature of linked lists
- Iterative Reversal: Reverse lists by redirecting pointers iteratively
- Merge Sort: Merge sorted linked lists efficiently
- Dummy Node: Simplify edge cases with a sentinel node
- Brute Force: Try all possible approaches (often O(n²) or worse)
Strategy 1: Two Pointers (Fast & Slow)
The Two Pointers technique uses two pointers that traverse the linked list at different speeds. Typically, one pointer (slow) moves one step at a time while the other (fast) moves two steps. This strategy is particularly effective for finding middle elements, detecting cycles, or removing elements from the end. The key insight is that when the fast pointer reaches the end, the slow pointer will be at the middle.
When to use it
- Find the middle of a linked list
- Remove nth node from the end
- Detect cycles in a linked list
- Need to maintain a gap between two pointers
Time Complexity: O(n) | Space Complexity: O(1)
Problem: Remove Nth Node From End of List
Given the head of a linked list, remove the nth node from the end and return its head.
Implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public class ListNode
{
public int val;
public ListNode next;
public ListNode(int val = 0, ListNode next = null)
{
this.val = val;
this.next = next;
}
}
public class Solution
{
public ListNode RemoveNthFromEnd(ListNode head, int n)
{
ListNode p = head, q = head;
while (n > 0)
{
q = q.next;
n--;
}
if (q == null)
{
return head.next;
}
while (q.next != null)
{
p = p.next;
q = q.next;
}
p.next = p.next.next;
return head;
}
}
Key Insight: Maintain a gap of n nodes between two pointers. When the fast pointer reaches the end, the slow pointer is at the node before the one to remove.
Strategy 2: Floyd’s Cycle Detection
Floyd’s Cycle Detection Algorithm (also known as the Tortoise and Hare algorithm) is a pointer algorithm that uses two pointers moving at different speeds to detect cycles in a linked list. The slow pointer moves one step at a time while the fast pointer moves two steps. If there’s a cycle, the fast pointer will eventually catch up to the slow pointer inside the cycle. This elegant algorithm was invented by Robert W. Floyd and uses O(1) space complexity.
When to use it
- Detect if a linked list has a cycle
- Find the start of a cycle
- Determine cycle length
- Need constant space for cycle detection
Time Complexity: O(n) | Space Complexity: O(1)
Problem: Linked List Cycle
Given a linked list, determine if it has a cycle in it.
Implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public class ListNode
{
public int val;
public ListNode next;
public ListNode(int x)
{
val = x;
next = null;
}
}
public class Solution
{
public bool HasCycle(ListNode head)
{
ListNode p = head;
ListNode q = head;
while (q != null && q.next != null)
{
p = p.next;
q = q.next.next;
if (p == q)
{
return true;
}
}
return false;
}
}
Key Insight: If there’s a cycle, the fast pointer will eventually meet the slow pointer. If there’s no cycle, the fast pointer will reach null.
Strategy 3: Recursion
Recursion is a natural fit for linked lists because of their recursive structure: a linked list is either empty or consists of a node followed by a linked list. Recursive solutions often provide elegant, concise code for problems like reversal, merging, or tree-like operations on linked lists. The base case typically handles an empty list or a single node, while the recursive case processes the current node and delegates the rest to a recursive call.
When to use it
- Problem has a natural recursive structure
- Need to process nodes from end to beginning
- Reversing a linked list
- Merging or combining linked lists
Time Complexity: O(n) | Space Complexity: O(n) due to call stack
Problem: Reverse Linked List
Reverse a singly linked list using recursion.
Implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class ListNode
{
public int val;
public ListNode next;
public ListNode(int val = 0, ListNode next = null)
{
this.val = val;
this.next = next;
}
}
public class Solution
{
private (ListNode, ListNode) Reverse(ListNode head)
{
if (head.next == null) return (head, head);
var (h, t) = Reverse(head.next);
t.next = head;
head.next = null;
return (h, head);
}
public ListNode ReverseList(ListNode head)
{
if (head == null) return null;
return Reverse(head).Item1;
}
}
Key Insight: Recursively reverse the rest of the list, then attach the current node at the end. The base case is when we reach the last node, which becomes the new head.
Iterative Alternative:
1
2
3
4
5
6
7
8
9
10
11
12
public class Solution {
public ListNode ReverseList(ListNode head) {
ListNode h = new ListNode();
while (head != null) {
var p = head;
head = head.next;
p.next = h.next;
h.next = p;
}
return h.next;
}
}
Strategy 4: Merge Sort
Merge Sort for linked lists is an efficient O(n log n) sorting algorithm that works by dividing the list into two halves, recursively sorting each half, and then merging the sorted halves back together. The merge operation is the key component and can also be used independently to merge two already-sorted linked lists. Unlike array-based merge sort, linked list merge sort doesn’t require extra space for the merge operation since we can rearrange pointers instead of copying elements.
When to use it
- Merge two or more sorted linked lists
- Sort a linked list efficiently
- Combine ordered sequences
- Need stable sorting
Time Complexity: O(m + n) for merge | Space Complexity: O(1)
Problem: Merge Two Sorted Lists
Merge two sorted linked lists and return it as a sorted list.
Implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public class ListNode
{
public int val;
public ListNode next;
public ListNode(int val = 0, ListNode next = null)
{
this.val = val;
this.next = next;
}
}
public class Solution
{
public ListNode MergeTwoLists(ListNode list1, ListNode list2)
{
ListNode head = new ListNode(0);
ListNode p = head;
head.next = list1;
while (p.next != null && list2 != null)
{
if (p.next.val > list2.val)
{
ListNode node = list2;
list2 = list2.next;
node.next = p.next;
p.next = node;
}
p = p.next;
}
if (list2 != null)
{
p.next = list2;
}
return head.next;
}
}
Key Insight: Use a dummy node to simplify edge cases. Compare values from both lists and always attach the smaller node to the result list.
Problem: Merge K Sorted Lists
Merge k sorted linked lists and return it as one sorted list.
Implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
public class Solution
{
public ListNode MergeKLists(ListNode[] lists)
{
if (lists == null || lists.Length == 0)
return null;
while (lists.Length > 1)
{
List<ListNode> mergedLists = new List<ListNode>();
for (int i = 0; i < lists.Length; i += 2)
{
ListNode l1 = lists[i];
ListNode l2 = (i + 1 < lists.Length) ? lists[i + 1] : null;
mergedLists.Add(MergeTwoLists(l1, l2));
}
lists = mergedLists.ToArray();
}
return lists[0];
}
private ListNode MergeTwoLists(ListNode list1, ListNode list2)
{
ListNode dummy = new ListNode(0);
ListNode current = dummy;
while (list1 != null && list2 != null)
{
if (list1.val < list2.val)
{
current.next = list1;
list1 = list1.next;
}
else
{
current.next = list2;
list2 = list2.next;
}
current = current.next;
}
current.next = list1 ?? list2;
return dummy.next;
}
}
Key Insight: Divide and conquer approach - repeatedly merge pairs of lists until only one list remains. This reduces time complexity from O(kN) to O(N log k) where k is the number of lists.
Strategy 5: Dummy Node Technique
The Dummy Node (also called sentinel node) is a technique where you create a temporary node at the beginning of the list to simplify edge cases and make code cleaner. Instead of handling special cases when the head changes, you always have a fixed starting point. After all operations, you simply return dummy.next as the actual head. This technique is particularly useful when you need to modify the head of the list or build a new list.
When to use it
- Head of the list might change
- Building a new list from scratch
- Need to simplify insertion operations
- Avoid special casing the first node
Time Complexity: O(n) | Space Complexity: O(1)
Example Pattern:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public ListNode SomeOperation(ListNode head)
{
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode current = dummy;
// Perform operations using current
while (current.next != null)
{
// Process nodes
current = current.next;
}
return dummy.next;
}
Key Insight: The dummy node eliminates the need to check if you’re at the head of the list, making insertions and deletions uniform throughout the list.
Strategy 6: In-Place Manipulation
In-Place Manipulation involves modifying the linked list structure by redirecting pointers without using additional data structures. This approach is crucial for achieving O(1) space complexity. Common operations include reversing sections, reordering nodes, or partitioning the list based on certain criteria. The key is to carefully track pointers (previous, current, next) and update them in the correct order to avoid losing references.
When to use it
- Need O(1) space complexity
- Reordering or rearranging nodes
- Reversing part or all of the list
- Partitioning the list
Time Complexity: O(n) | Space Complexity: O(1)
Problem: Reorder List
Reorder list from L₀→L₁→…→Lₙ₋₁→Lₙ to L₀→Lₙ→L₁→Lₙ₋₁→L₂→Lₙ₋₂→…
Implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
public class Solution
{
public void ReorderList(ListNode head)
{
if (head == null || head.next == null)
return;
// Step 1: Find middle
ListNode slow = head, fast = head;
while (fast.next != null && fast.next.next != null)
{
slow = slow.next;
fast = fast.next.next;
}
// Step 2: Reverse second half
ListNode second = slow.next;
slow.next = null;
ListNode prev = null;
while (second != null)
{
ListNode temp = second.next;
second.next = prev;
prev = second;
second = temp;
}
// Step 3: Merge two halves
ListNode first = head;
second = prev;
while (second != null)
{
ListNode temp1 = first.next;
ListNode temp2 = second.next;
first.next = second;
second.next = temp1;
first = temp1;
second = temp2;
}
}
}
Key Insight: Break the problem into three steps: find the middle, reverse the second half, then merge alternately. Each step uses O(1) space.
Strategy 7: Brute Force
Brute Force approaches for linked lists typically involve using extra data structures (arrays, hash tables) to simplify the problem. While these solutions are often easier to implement and understand, they use O(n) extra space and may not be optimal. However, they serve as excellent starting points for understanding the problem before optimizing to in-place solutions.
When to use it
- Problem size is small
- Need to establish correctness first
- Extra space is acceptable
- Baseline for comparison
Time Complexity: O(n) to O(n²) | Space Complexity: O(n)
Example: Store in array first
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class Solution
{
public void ReorderListBruteForce(ListNode head)
{
// Convert to array
List<ListNode> nodes = new List<ListNode>();
ListNode current = head;
while (current != null)
{
nodes.Add(current);
current = current.next;
}
// Reorder using array indices
int left = 0, right = nodes.Count - 1;
while (left < right)
{
nodes[left].next = nodes[right];
left++;
if (left == right) break;
nodes[right].next = nodes[left];
right--;
}
nodes[left].next = null;
}
}
Key Insight: Converting to an array gives random access but uses O(n) extra space. This is acceptable when clarity is prioritized over space efficiency.
Strategy Selection Guide
| Problem Type | Strategy | Time | Space |
|---|---|---|---|
| Find middle element | Two Pointers (Fast & Slow) | O(n) | O(1) |
| Detect cycle | Floyd’s Cycle Detection | O(n) | O(1) |
| Reverse list | Recursion or Iteration | O(n) | O(n) or O(1) |
| Merge sorted lists | Merge Sort | O(n+m) | O(1) |
| Remove nth from end | Two Pointers | O(n) | O(1) |
| Reorder list | In-Place Manipulation | O(n) | O(1) |
| Head might change | Dummy Node | O(n) | O(1) |
| Simplify problem first | Brute Force (Array) | O(n) | O(n) |
Pattern Recognition Tips
- Need to find middle? → Think Fast & Slow Pointers
- Cycle detection? → Think Floyd’s Cycle Detection
- Process from end to start? → Think Recursion
- Merge or combine lists? → Think Merge Sort pattern
- Head changes often? → Think Dummy Node
- Reorder or reverse? → Think In-Place Manipulation
- Gap of n nodes? → Think Two Pointers with offset
Common Pitfalls
- Losing references: Always store
nextbefore modifying pointers - Null pointer exceptions: Check
node != nullandnode.next != null - Edge cases: Handle empty lists, single nodes, and two-node lists
- Infinite loops: Ensure loop termination conditions are correct
- Not using dummy node: Makes code more complex with special cases
Advanced Techniques
Slow/Fast Pointer Variants
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// Find middle (slow ends at middle)
ListNode slow = head, fast = head;
while (fast != null && fast.next != null)
{
slow = slow.next;
fast = fast.next.next;
}
// Find middle-1 (slow ends before middle)
ListNode slow = head, fast = head.next;
while (fast != null && fast.next != null)
{
slow = slow.next;
fast = fast.next.next;
}
Three Pointer Technique
1
2
3
4
5
6
7
8
9
10
// For in-place reversal
ListNode prev = null, current = head, next = null;
while (current != null)
{
next = current.next; // Save next
current.next = prev; // Reverse link
prev = current; // Move prev forward
current = next; // Move current forward
}
// prev is now the new head
Conclusion
Mastering these algorithmic strategies is essential for solving linked list problems efficiently. The key is to:
- Identify the pattern in the problem statement
- Choose the right strategy based on constraints
- Handle edge cases carefully (null, single node, cycles)
- Optimize space when possible using in-place techniques
- Practice pointer manipulation to avoid losing references
Practice these strategies on LeetCode to build intuition for which approach to use. With time, pattern recognition becomes second nature, and you’ll quickly identify the optimal strategy for any linked list problem you encounter. Remember: linked lists are all about pointers - master them and you’ll master linked lists! 🚀
References
LeetCode. (2024). Linked List Problems. https://leetcode.com/tag/linked-list/
Cormen, T. H., Leiserson, C. E., Rivert, R. L. & Stein, C. (2009). Introduction to Algorithms (3rd ed.). MIT Press.
Floyd, R. W. (1967). Noncursive Algorithms. Communications of the ACM.